
Lambda架构概述
- 2022-07-01 10:11:46
- 1154次 极悦
Lambda 架构是一种数据处理部署模型,组织使用该模型将传统批处理管道与快速实时流管道相结合以进行数据访问。它是 IT 和开发组织工具包中的一种常见架构模型,因为面对大量快速生成的数据(通常称为“大数据”),企业努力变得更加数据驱动和事件驱动。
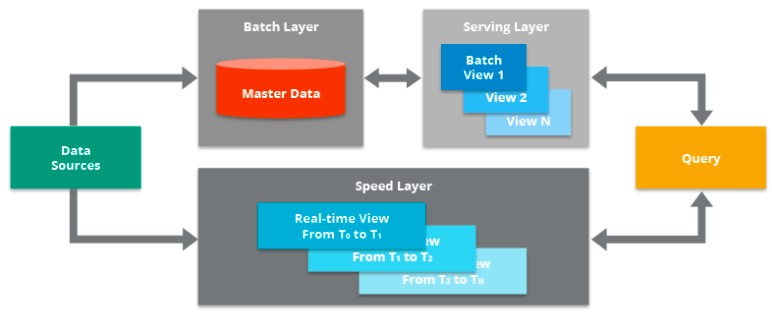
Lambda 架构既包含传统的批处理数据管道,也包含用于实时数据的快速流传输管道,以及用于响应查询的服务层。
在上图中,您可以看到 Lambda 架构的主要组件:
数据源。数据可以从各种来源获得,然后可以包含在 Lambda 架构中进行分析。这个组件通常是像 Apache Kafka 这样的流式源,它本身不是原始数据源,而是一个可以保存数据的中间存储,以便为 Lambda 架构的批处理层和速度层提供服务。数据同时传送到批处理层和速度层,以实现并行索引工作。
批处理层。该组件将所有进入系统的数据保存为批处理视图,以准备索引。输入数据保存在一个模型中,该模型看起来像是对记录系统进行的一系列更改/更新,类似于更改数据捕获 (CDC)系统的输出。通常,这只是逗号分隔值 (CSV) 格式的文件。数据被视为不可变且仅追加,以确保所有传入数据的可信历史记录。像 Apache Hadoop 这样的技术通常被用作一种系统,用于以经济高效的方式摄取数据以及存储数据。
服务层。该层对最新的批处理视图进行增量索引,以使其可供最终用户查询。该层还可以重新索引所有数据以修复编码错误或为不同的用例创建不同的索引。服务层的关键要求是以极其并行的方式完成处理,以最大限度地减少索引数据集的时间。在运行索引作业时,新到达的数据将排队等待在下一个索引作业中进行索引。
速度层。该层通过索引最近添加的尚未被服务层完全索引的数据来补充服务层。这包括服务层当前正在索引的数据以及在当前索引作业开始后到达的新数据。由于最新数据添加到系统的时间与最新数据可用于查询的时间之间存在预期滞后(由于执行批量索引工作需要时间),因此取决于速度层索引最新数据以缩小这一差距。
该层通常利用流处理软件近乎实时地索引传入数据,以最大限度地减少获取可用于查询的数据的延迟。首次引入 Lambda 架构时,Apache Storm 是部署中使用的领先流处理引擎,但此后其他技术作为该组件的候选技术(如Hazelcast Jet、Apache Flink 和 Apache Spark Streaming)越来越受欢迎。
查询。该组件负责向服务层和速度层提交最终用户查询并合并结果。这为最终用户提供了对所有数据(包括最近添加的数据)的完整查询,以提供近乎实时的分析系统。
选你想看










你适合学Java吗?4大专业测评方法
代码逻辑 吸收能力 技术学习能力 综合素质
先测评确定适合在学习
价值1998元实验班免费学
 在线咨询
在线咨询
 免费试学
免费试学