
Java中set集合详解
- 2022-09-23 09:45:55
- 1409次 极悦
set集合框架体系图

set集合介绍
Set接口继承了Collection接口,含有许多常用的方法。
int size();返回集合的长度
boolean isEmpty();判断集合是否为空
boolean contains(Object o);是否包含某个值
boolean add(E e);添加元素
boolean remove(Object o);删除元素
Set接口的存储特点是无序不可重复,可以存放唯一一个null值,Set的常用实现类有HashSet,TreeSet。
Set集合的遍历方式有三种
1.直接打印System.out.println(set);
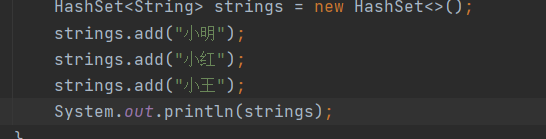
2.增强for循环遍历
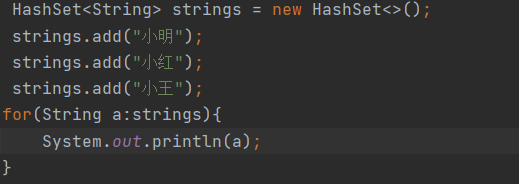
3.迭代器遍历

Set集合的实现类
HashSet
1.HashSet实现了Cloneable, Serializable两个接口。
Cloneable:实现了clone()方法可以实现克隆功能
Serializable:表示可以被序列化传输。
2.HashSet的底层结构
HashSet的底层是通过HashMap实现
HashMap是通过数组加链表加红黑树实现的。

(1)add()方法
调用Map集合中的put方法。
将要添加的元素作为Map集合中的key,PRESENT作为Map集合中的Value;
PERSENT的值为new Object( );
HashCode相同会发生什么?
产生hash碰撞,hash码相同,则通过key的equals()方法比较值是否相同.
key值不相等:则会在该节点的链表结构上新增一个节点(如果链表长度>=8且 数组节点数>=64 链表结构就会转换成红黑树)
key值相等:则用新的value替换旧的value


(2)remove()方法
也调用的是Map集合中的remove方法

(3)contains()方法

由此可见HashSet的底层是借助与HashMap实现的,底层的初始化原理,扩容原理都和HashSet集合相同·
3.HashSet的去重原理
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果Hash相同并且数值相同直接替换即可
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p是一个红黑树结点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
TreeSet
1.TreeSet是一个有序的集合,它的作用是提供有序的Set集合。它继承了AbstractSet抽象类,实现了NavigableSet,Cloneable,Serializable接。它是非线程安全的,TreeSet是基于TreeMap实现的
TreeMap是通过红黑树实现的
2.TreeSet的基本使用
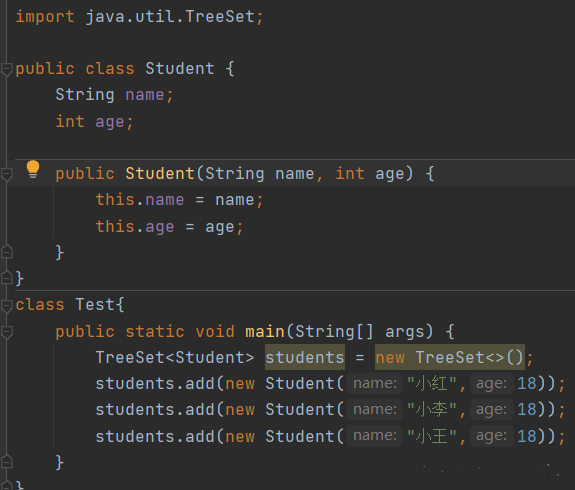
如果我们像使用HashSet一样使用TreeSet这样是否会报错呢?
答案是报错

如何解决呢?解决办法有两种
解决方法一:(自然排序)、
在Student类中实现Comparable接口,重写compareTo方法即可

解决方法二:定制排序
在创建TreeMap对象时,传入一个Comparator接口,并实现里面的compare方法。

3.TreeSet的构造方法
TreeSet提供了五种构造方法。
(1)无参构造方法,创建一个TreeMap类。
public TreeSet() {
this(new TreeMap<E,Object>());
}
(2)指定TreeSet的比较器
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
(3)创建一个TreeSet,并将Collection c集合中的元素加入到TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
addAll©;
}
(4)构造一个包含相同元素并使用与指定排序集相同的顺序的新树集。
public TreeSet(SortedSet s) {
this(s.comparator());
addAll(s);
}
(5)构造一个由指定的可导航地图支持的集合。
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
4.TreeSet的去重方法:前面讲到hashSet去重的方法是hashcode和equals方法判断相同则覆盖,TreeSet是通过compareTo方法的返回值来判断是否相同,如果返回值为0则认定是重复元素
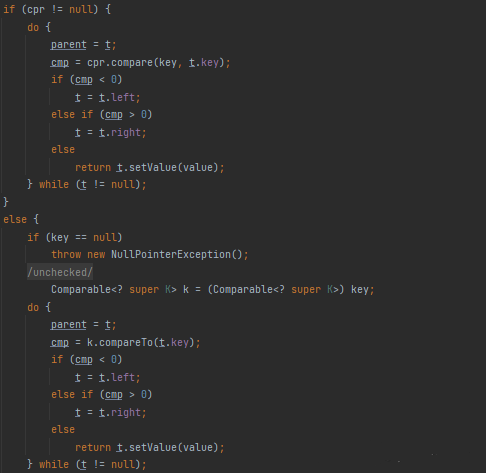
5.TreeSet的常用方法
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}`
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
public void clear() {
m.clear();
}
m为底层的HashMap集合,
LinkedHashSet
LinkedHashSet是一个哈希表和链表的结合,且是一个双向链表
并且linkedHashSet是一个非线程安全的集合。如果有多个线程同时访问当前linkedhashset集合容器,并且有一个线程对当前容器中的元素做了修改,那么必须要在外部实现同步保证数据的准确性。
LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法操作上又与 HashSet 相同
TreeSet和HashSet的区别
1.TreeSet 是二叉树(红黑树)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2.HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复。
3.HashSet要求放入的对象实现HashCode()和equals()方法,TreeSet要求放入的对象继承Comparable接口并实现compareTo方法或者在建TreeMap对象时,传入一个Comparator接口,并实现里面的compare方法
选你想看










你适合学Java吗?4大专业测评方法
代码逻辑 吸收能力 技术学习能力 综合素质
先测评确定适合在学习
价值1998元实验班免费学
 在线咨询
在线咨询
 免费试学
免费试学