
比较常用的JVM配置参数
- 2022-10-24 09:28:15
- 847次 极悦
1.Trace 跟踪参数
在Eclipse中,如何打开GC的监控日志
选择菜单栏Run -> Run Configurations -> Java Application -> 选择自己的项目 -> 在右侧找到Arguments选项卡 -> 在VM arguments中填写参数,具体参数在下面会有说明。
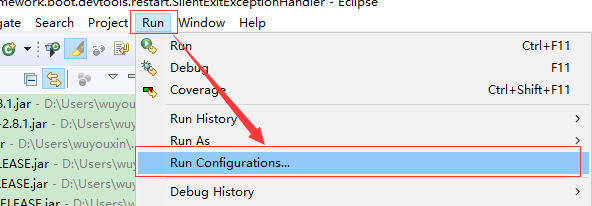
根据右侧Main的project和下面Main class确定自己监控的main方法
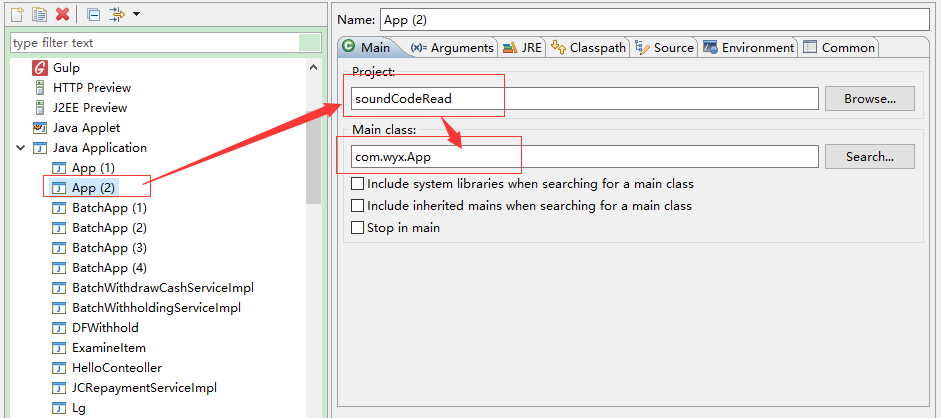
在右侧找到Arguments选项卡 -> 在VM arguments中填写参数
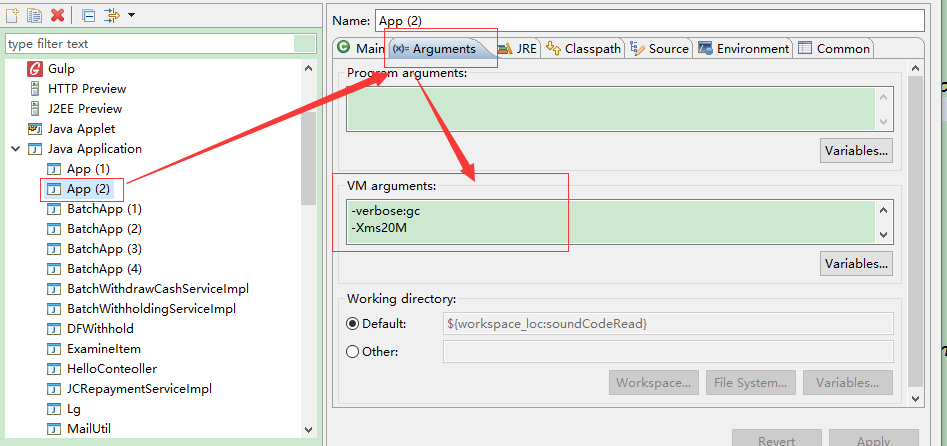
-verbose:gc(打开GC的跟踪日志)
-XX:+printGC(打开GC的log的开关,简要日志)

上图为我自己的一个小项目中的gc简要的日志信息 其中 9865k 表示在堆中GC之前使用了9865k的空间,2891k 表示GC之后使用2891k的空间,剩空间为19456k ,本次GC使用的时间为0.0021802 secs
-XX:+PrintGCDetails(打印GC的详细信息)

上图我们以第二条为例:PSYoungGen表示新生代 GC之前为9214k,GC之后为 1016K,新生代总大小为9216k,GC所使用的时间为0.0016505 secs。而后面的信息则为上面简要信息中的内容。user 总计本次 GC 总线程所占用的总 CPU 时间 ,sys – OS 调用 or 等待系统时间,real – 应用暂停时间,如果GC 线程是 Serial Garbage Collector单线程的方式的话, real time 等于user 和 system 时间之和.
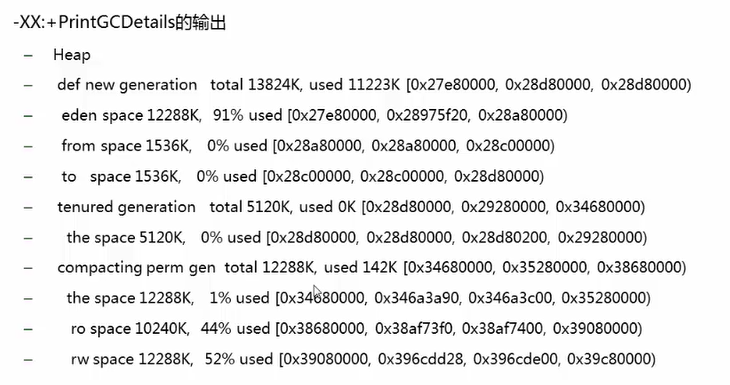
(def new generation)新生代
(total 13824K)共有13824K空间可用,(used 11223K)有11223K被使用。
(eden space 12288k.91%)伊甸区 对象出生的地方有 12288K 的空间,有91%已经被占用
(from space 1536K,0%)s0区 1536K空间,被占用为0
(to space 1536K,0%)s0区 1536K空间,被占用为0
(tenured generation)老年代
(the space 5120K,0%)有5120K空间被占用为0
(compacting perm gen)永久代
(the space 12288k,1%)有12288K空间被占用为1%,在jdk5.0之后在串行GC下有一个永久区共享,打开共享之后一些基础的java类可用被所有的jvm共同使用,所以被占用率较小.
(ro space 10240K,44%)只读共享区间 有10240K空间 44%被占用
(rw space 12288K,52%)可读可写共享区间 有12288K空间,52%被占用
(而最后[]号中的3个值为地址值,分别表示当前内存区域的地址开始地址,当前地址,最大地址上限)

上图为我自己获取到的jvm日志信息,永久代被删除,取而代之的是Metaspace 元数据区域,这是 java8 所做的替换。
持久代中存的内容:
JVM中类的元数据在Java堆中的存储区域。
Java类对应的HotSpot虚拟机中的内部表示。
类的层级信息,字段,名字。
方法的编译信息及字节码。
变量
常量池和符号解析
元空间的特点:
充分利用了Java语言规范中的好处:类及相关的元数据的生命周期与类加载器的一致。
每个加载器有专门的存储空间
只进行线性分配
不会单独回收某个类
省掉了GC扫描及压缩的时间
元空间里的对象的位置是固定的
如果GC发现某个类加载器不再存活了,会把相关的空间整个回收掉
-XX:+PrintGCTimeStamps(打印GC发生的时间戳)
-Xloggc:log/ge.log(指定GC.log的位置,以文件形式输出)
-XX:+PrintHeapAtGC(每一次GC后都打印出堆信息)
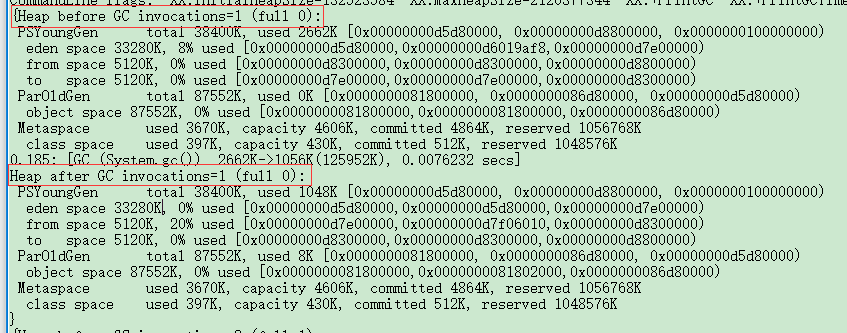
Heap before GC 表示GC之前的堆信息
Heap after GC 表示GC之后的堆信息
-XX:+TraceClassLoading(监控类加载,可以在程序运行时检出哪些类被加载了)

-XX:+PrintClassHistogram(加入此参数,在运行时不会有其他东西输出,但是在按下Ctrl+Break后可以打印出类的信息,类的直方图)

上述4个列分别代表了(num)序号,(instances)实例数量,(bytes)总占用空间,(class name)类型
([B)有890617个byte数组,占用了470266000的空间
(java.util.HashMap$Node)hashMap的结点有890643个占用21375432的空间
2.堆的分配参数
-Xmx(最大堆的空间)
-Xms(最小堆的空间)

System.out.println("系统最大使用空间:Xmx=" + Runtime.getRuntime().maxMemory()/1024.0/1024 + "M");
System.out.println("系统可用空间:free mem=" + Runtime.getRuntime().freeMemory()/1024.0/1024 + "M");
System.out.println("系统中分配到的空间:total mem=" + Runtime.getRuntime().totalMemory()/1024.0/1024 + "M");
我们可以通过上述代码来获取系统中实际使用的空间大小。

我们可以看到,我的系统中最大堆空间为18.0M,系统分配到的空间为9.5M,是比较接近于我们自己设置的值,系统目前可用空间为7.9M,此时系统存在可用空间。
当我在我的系统中加入一行代码,创建一个1M的byte数组
byte []b = new byte[1024*1024*1];

此时发现,系统可用空间整好少了1M,而总空间和系统中分配到的空间还是没变的,如果我们的系统使用的空间是小于系统分配的空间时,系统分配空间会尽可能维持在最小空间10M附近,只有系统使用的空间大于10M后,系统分配空间才会去扩展。我们在代码中创建一个10M的byte数组来看。

此时,系统使用的空间肯定是大于10M的,所以我们的系统分配的空间已经扩展到了16M.如果我们创建一个大于20Mbyte的话就会发生OOM了,因为系统已经限制最大空间为20M。

-Xmn (设置新生代的大小)
-XX:NewRatio(设置新生代和老年代的比值,如果设置为4则表示(eden+from(或者叫s0)+to(或者叫s1)): 老年代 =1:4),即年轻代占堆的五分之一
-XX:SurvivorRatio(设置两个Survivor(幸存区from和to或者叫s0或者s1区)和eden区的比),8表示两个Survivor:eden=2:8,即Survivor区占年轻代的五分之一
下面来看一个例子(jdk6)
//将jvm参数设置为-Xmx20m -Xms20m -Xmn1m -XX:+PrintGCDetails(将新生代的大小设置为1M)
byte []b = null;
for (int i = 0; i < 10; i++) {
b = new byte[1024*1024*1];
}
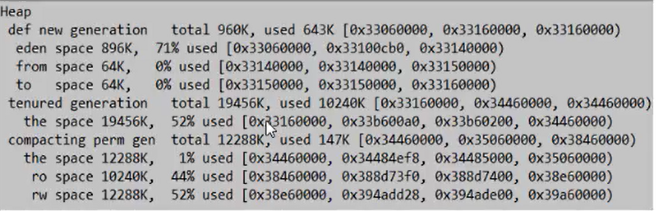
上图为堆信息,没有发生过GC,新生代只有896K,1Mbyte无法分配到新生区,所以所有的数据都被分配到老年代,老年代的内存被占用的为10240K正好是byte的大小。
我们将上述代码的新生代的内存进行扩大,调整到15M -Xmx20m -Xms20m -Xmn15m -XX:+PrintGCDetails
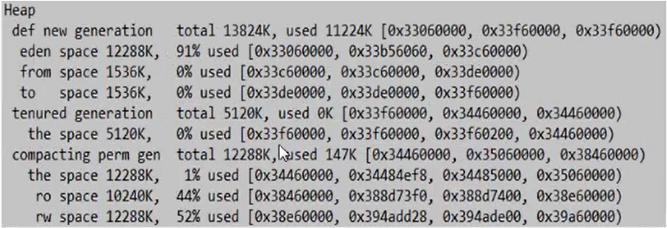
我们发现修改新生代之后也没有发生GC,而是将数据全部分配到了新生代13824K,老年代却没有使用。
我们将上述代码的新生代的内存进行减小,调整到不大不小的位置,调整到7M -Xmx20m -Xms20m -Xmn7m -XX:+PrintGCDetails
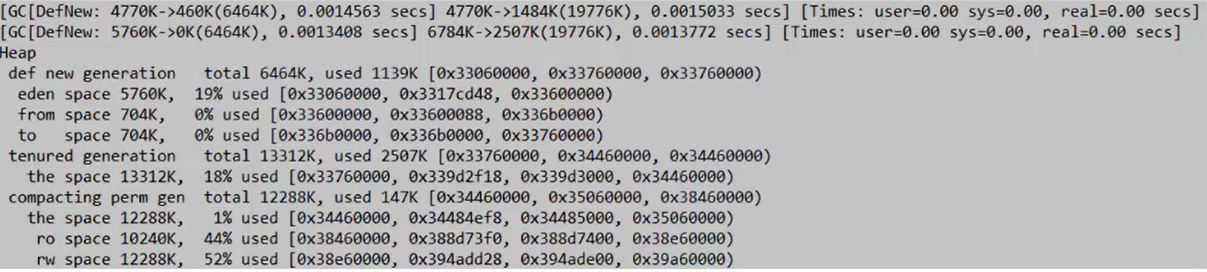
此时发现GC被触发了2次,第一次回收了3M左右,第二次回收了4M左右,此时发现新生代被使用1139K,老年代被使用2507K,因为form to(s0 s1)区域的大小为704K,不足1M所以才GC时还是有一部分数据被放入了老年代。
接下来,我们将幸存代的大小进行调整from:to:endn=1:1:2, -Xmx20m -Xms20m -Xmn7m XX:SurvivorRatio=2 -XX:+PrintGCDetails
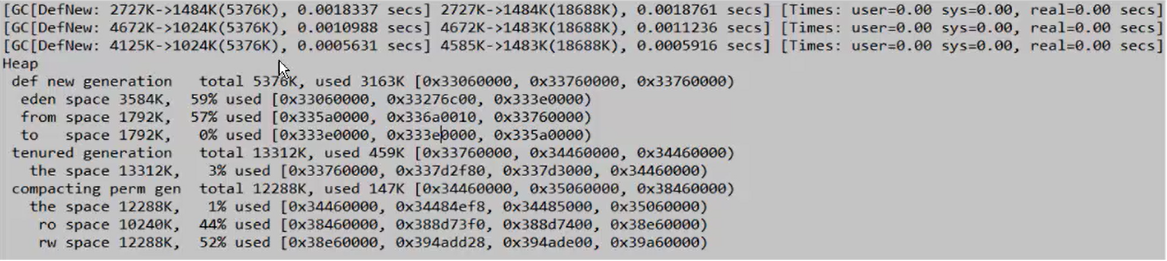
此时幸存代可以正常使用,GC发生了3次。第一次回收了1M,第二次回收了3M,第三次回收了3M,新生代占用了3M,此时新产生的数据没有进入到老年代。
接下来,继续调整新生代和老年代的比例为1, -Xmx20m -Xms20m -XX:NewRatio=1 XX:SurvivorRatio=2 -XX:+PrintGCDetails
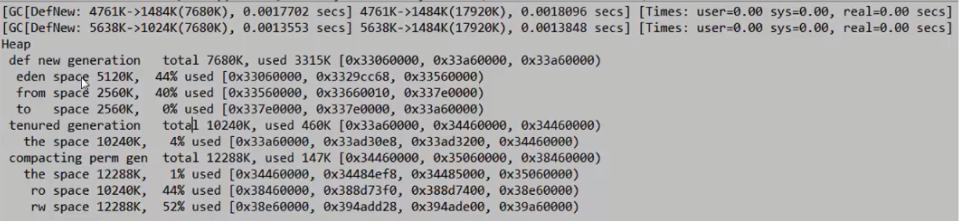
此时GC进行了2次回收第一次回收了3M,第二次回收了4M,还有3M在新生代,也没有数据进入老年代,并且GC只执行了2次,所以对于上一种配置效率就有所提高,因为GC时很消耗效率的。幸存代空间越大,对系统资源的浪费还是挺严重的,所以合理的分配幸存代,堆系统的效率也会有很大的帮助。
接下来,继续调整幸存代的大小进行调整from:to:endn=1:1:3, -Xmx20m -Xms20m -XX:NewRatio=1 XX:SurvivorRatio=3 -XX:+PrintGCDetails,此时,from和to的幸存区有2M,而endn区有6M
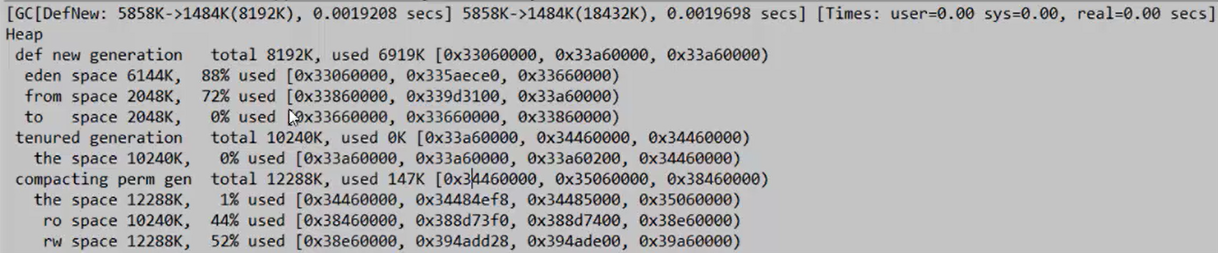
此时GC只进行了1次,我们对幸存代的大小进行了合理的减小,这样更有利于内存的合理使用。
-XX:+HeapDumpOnOutOfMemoryError(将OOM时的堆信息导出到文件)
如果系统出现OOM一般情况系统有可能会down掉,但是我们排查问题时需要场景重现是比较困难的,所以当我们输出了OOM的异常时,就可以直接查看,找出导致OOM的原因
-XX:+HeapDumpPath=XXXX(导出OOM堆信息文件的路径)
-XX:OnOutOfMemoryError(在系统出现OOM时,执行一个脚本,可以发送邮件,报警或者是重启程序)
-XX:PermSize(设置永久代的初始空间大小)
-XX:MaxParmSize(设置永久代的最大空间)
在使用CGLIB等库的时候,可能会产生大量的类,这些类就有可能会撑爆永久区导致OOM
我们来看下面实例:
for (int i = 0; i < 100000; i++) {
CglibBean c = new CglibBean(new HashMap<String, String>());
}
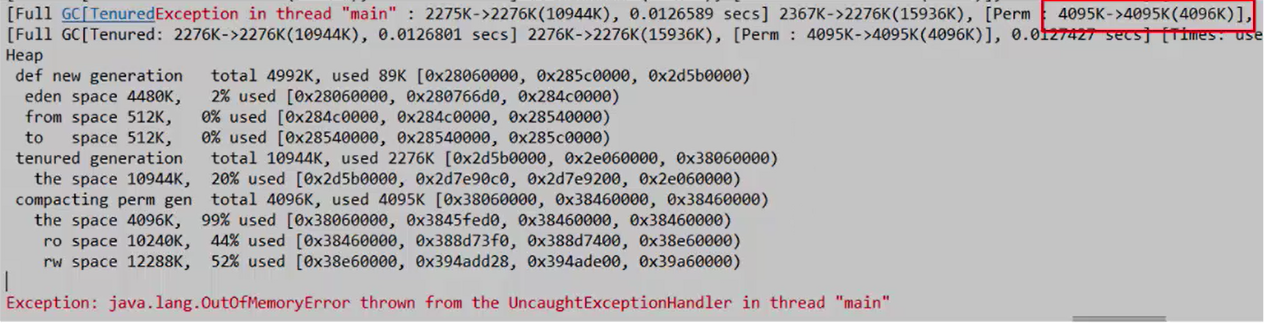
当发生OOM时,我们发现永久区的空间已经是满了,然后发生GC时永久区的内容也无法被回收,所以导致了OOM,此时新生代只占用了2%,老难带占用了20%,而老年代使用率为99%.
总结:
根据实际事情调整新生代和幸存代的大小,因为各个系统的情况都不一样,所以需要自己调试而找到一个相对较优的分配方案。
官方推荐新生代占堆的3/8
幸存代占新生代的1/10
在OOM时,及得Dump出堆,确保可以排查现场问题
在堆空间没有使用完时也有可能会产生OOM,此时有可能是永久代被撑爆。
3.栈大小的分配
栈是每一个线程都有的,他是线程私有的一块内存区域.栈中主要是由帧组成,而帧中是每个方法的局部变量表,操作数表,和指向常量池的引用和返回地址等组成。一般只有几百K,但是它的大小决定了线程的多少和调用函数的深度,而且每个线程都有独立的栈空间。
-Xss(设置栈空间的大小)
下面看一个简单的例子:首先我们将栈空间设置为128K
private static int count = 0;
public static void recursion(long a, long b, long c) {
long e = 1, f = 2, g = 3, h = 4, i = 5, j = 6, k = 7, l = 8, m = 9;
count ++;
recursion(a, b, c);
}
public static void main(String[] args) {
try {
recursion(1, 2, 3);
} catch (Throwable e) {
System.out.println("deep of calling = " + count);
e.printStackTrace();
}
}

此时只执行了323次的递归。
然后我们将栈空间扩大到256K再来看结果:

此时递归执行竟然扩大到了1019,接近3倍,那么说明方法执行的深度由栈空间的大小所决定。
然后我们将局部变量e之后的局部变量都清除再来看结果:

我们发现,递归次数再次增加。此处说明方法执行的深度也由方法内局部变量表的个数所决定。
选你想看










你适合学Java吗?4大专业测评方法
代码逻辑 吸收能力 技术学习能力 综合素质
先测评确定适合在学习
价值1998元实验班免费学
 在线咨询
在线咨询
 免费试学
免费试学