
适用于Windows的Hadoop安装配置
- 2022-11-15 10:11:06
- 944次 极悦
安装 Hadoop 的步骤
安装 Java JDK 1.8
下载hadoop解压放在C盘下
在环境变量中设置路径
Hadoop目录下的配置文件
在data目录下创建文件夹datanode和namenode
编辑 HDFS 和 YARN 文件
在 Hadoop 环境中设置 Java Home 环境
安装完成。通过执行 start-all.cmd 进行测试
Hadoop的安装方式有两种
即单节点
多节点
单节点集群是指只有一个DataNode在运行,所有的NameNode、DataNode、ResourceManager和NodeManager都在一台机器上搭建。
这用于学习和测试目的。
因此,为了测试 Oozie 作业是否按正确的顺序安排了收集、聚合、存储和处理数据等所有过程,我们使用单节点集群。
与包含分布在数百台机器上的 TB 数据的大型环境相比,它可以在较小的环境中轻松高效地测试顺序工作流。
而在多节点集群中,有多个DataNode在运行,每个DataNode运行在不同的机器上。多节点集群在组织中实际用于分析大数据。在实时处理 PB 级数据时,需要将其分布在数百台机器上进行处理。因此,这里我们使用多节点集群。
设置单节点 Hadoop 集群
在 Windows 上安装 Hadoop 的先决条件
VIRTUAL BOX (For Linux) : 用于安装操作系统。
操作系统:您可以在基于 Windows 或 Linux 的操作系统上安装 Hadoop。Ubuntu 和 CentOS 是非常常用的。
JAVA:您需要在系统上安装 Java 8 包。
HADOOP:您需要 Hadoop 最新版本
1.安装Java
– Java JDK 链接下载
http://www.oracle.com/java/technologies/javase-jdk8-downloads.html
– 在 C:\Java 中提取并安装 Java
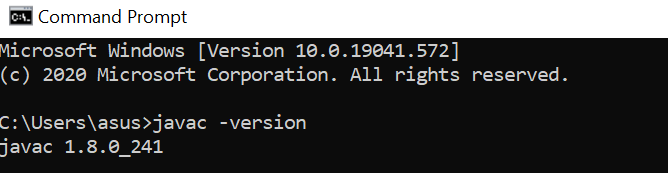
– 打开 cmd 并输入 -> javac -version
2.下载 Hadoop
– http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
– 解压到 C:\Hadoop
3.设置路径 JAVA_HOME 环境变量
4.设置路径 HADOOP_HOME 环境变量
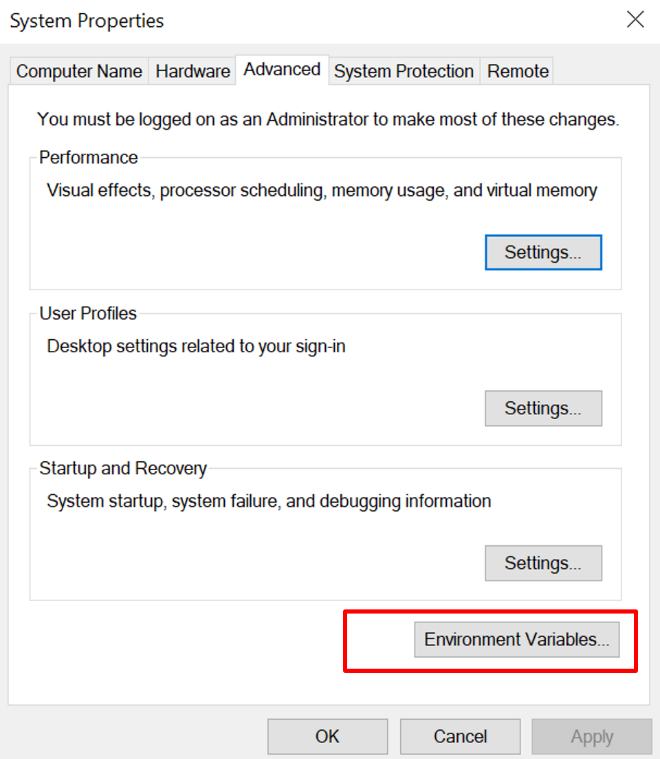
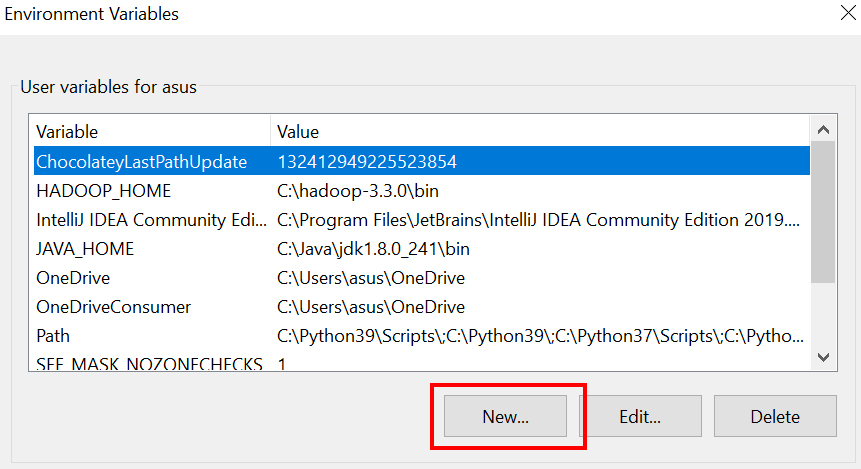
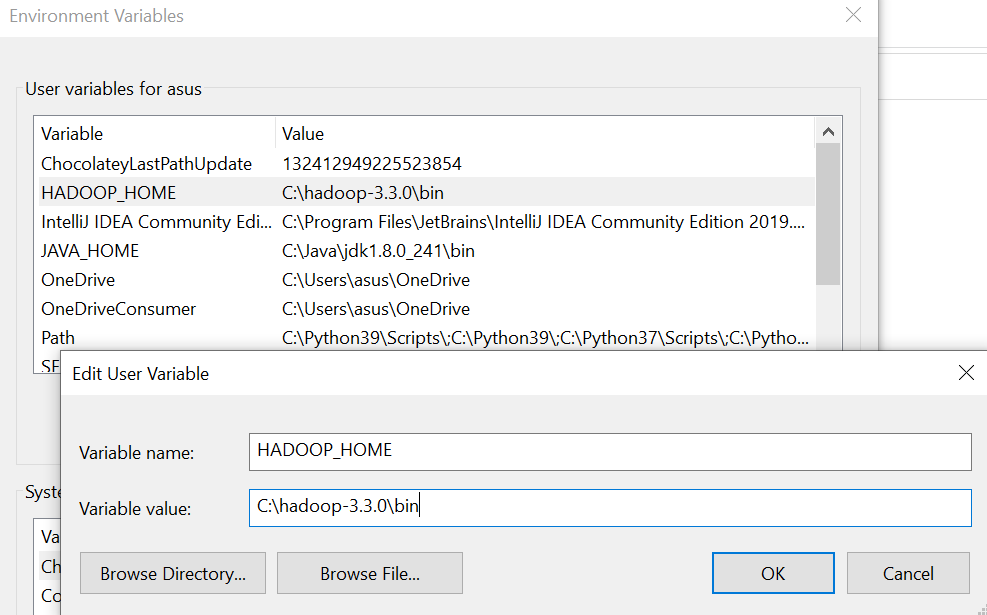
5.配置
编辑文件C:/Hadoop-3.3.0/etc/hadoop/core-site.xml,
将xml代码粘贴到文件夹中并保存
<配置>
<属性>
<名称>fs.defaultFS</名称>
<value>hdfs://localhost:9000</value>
</属性>
</配置>
将“mapred-site.xml.template”重命名为“mapred-site.xml”并编辑此文件 C:/Hadoop-3.3.0/etc/hadoop/mapred-site.xml,粘贴 xml 代码并保存此文件。
<配置>
<属性>
<名称>mapreduce.framework.name</名称>
<value>纱线</value>
</属性>
</配置>
在“C:\Hadoop-3.3.0”下创建文件夹“data”
在“C:\Hadoop-3.3.0\data”下创建文件夹“datanode”
在“C:\Hadoop-3.3.0\data”下创建文件夹“namenode”
编辑文件C:\Hadoop-3.3.0/etc/hadoop/hdfs-site.xml,
粘贴 xml 代码并保存此文件。
<配置>
<属性>
<name>dfs.replication</name>
<值>1</值>
</属性>
<属性>
<名称>dfs.namenode.name.dir</名称>
<值>/hadoop-3.3.0/data/namenode</值>
</属性>
<属性>
<名称>dfs.datanode.data.dir</名称>
<值>/hadoop-3.3.0/data/datanode</值>
</属性>
</配置>
编辑文件C:/Hadoop-3.3.0/etc/hadoop/yarn-site.xml,
粘贴 xml 代码并保存此文件。
<配置>
<属性>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</属性>
<属性>
<名称>yarn.nodemanager.auxservices.mapreduce.shuffle.class</名称>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</属性>
</配置>
编辑文件 C:/Hadoop-3.3.0/etc/hadoop/hadoop-env.cmd
通过关闭命令行
“JAVA_HOME=%JAVA_HOME%”而不是设置“JAVA_HOME=C:\Java”
6.Hadoop 配置
下载
http://github.com/brainmentorspvtltd/BigData_RDE/blob/master/Hadoop%20Configuration.zip
或者(对于 hadoop 3)
http://github.com/s911415/apache-hadoop-3.1.0-winutils
– 复制文件夹 bin 并替换现有的 bin 文件夹
C:\Hadoop-3.3.0\bin
– 格式化NameNode
– 打开 cmd 并键入命令“hdfs namenode –format”
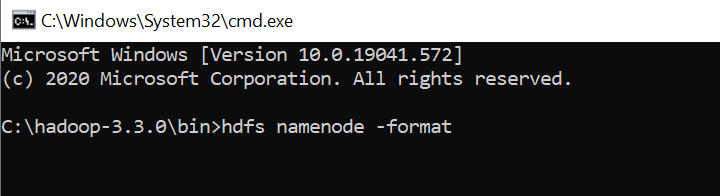
7.测试
– 打开 cmd 并将目录更改为 C:\Hadoop- 3.3.0 \sbin
– 输入 start-all.cmd
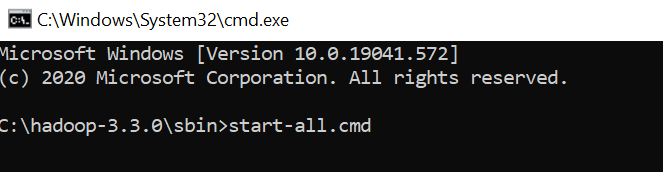
(或者你可以这样开始)
– 使用此命令启动名称节点和数据节点
– 输入 start-dfs.cmd
– 通过这个命令启动yarn
– 输入 start-yarn.cmd
确保这些应用程序正在运行
– Hadoop 名称节点
– Hadoop 数据节点
– 纱线资源管理器
– YARN 节点管理器
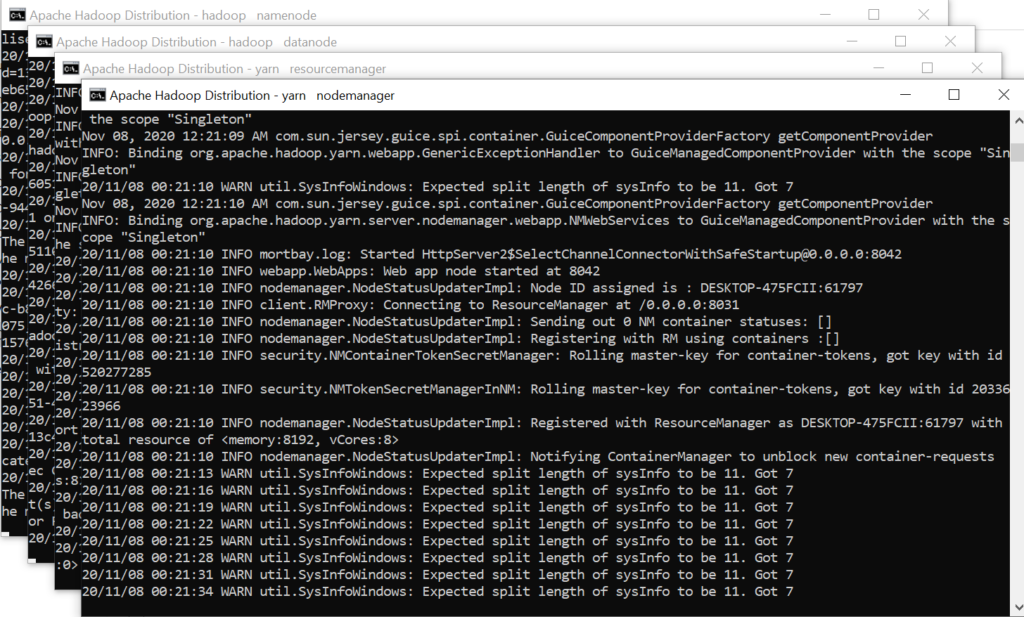
Open: http://localhost:8088

打开:http://localhost:9870
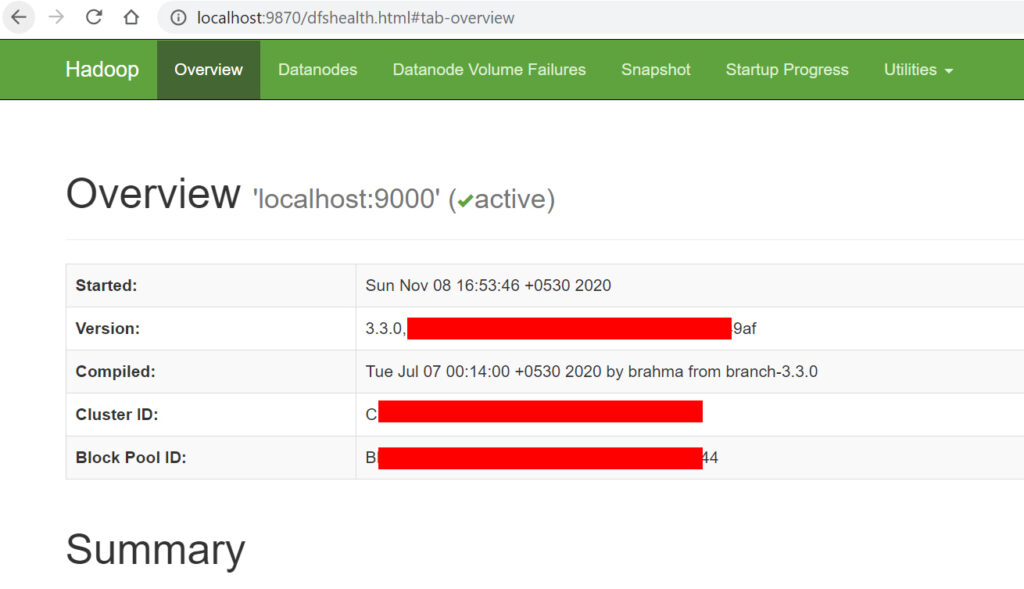
Hadoop 安装成功
选你想看










你适合学Java吗?4大专业测评方法
代码逻辑 吸收能力 技术学习能力 综合素质
先测评确定适合在学习
价值1998元实验班免费学
 在线咨询
在线咨询
 免费试学
免费试学