MySQL教程
分组查询主要涉及到两个子句,分别是:group by和having。
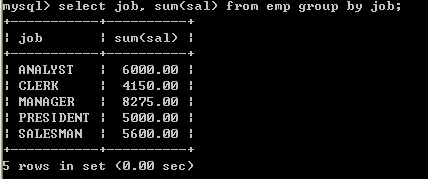
● 取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
select job, sum(sal) from emp group by job;
如果使用了order by,order by必须放到group by后面

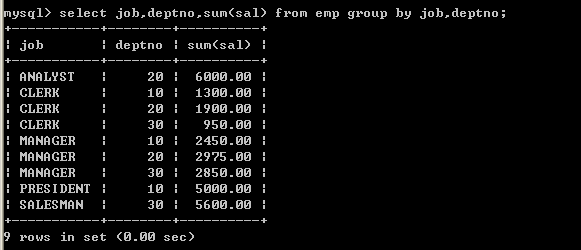
● 按照工作岗位和部门编码分组,取得的工资合计
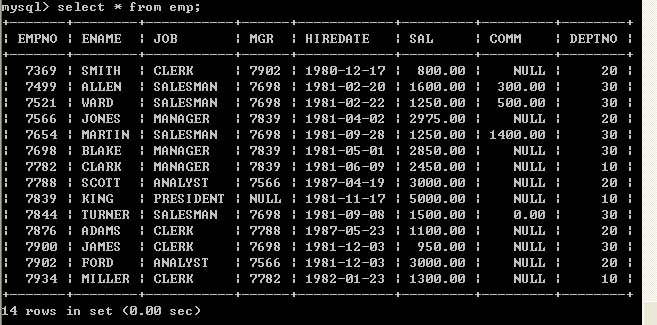
1、原始数据
2、分组语句
select job,deptno,sum(sal) from emp group by job,deptno;
mysql> select empno,deptno,avg(sal) from emp group by deptno;
+-------+--------+-------------+
| empno | deptno | avg(sal) |
+-------+--------+-------------+
| 7782 | 10 | 2916.666667 |
| 7369 | 20 | 2175.000000 |
| 7499 | 30 | 1566.666667 |
+-------+--------+-------------+
以上SQL语句在Oracle数据库中无法执行,执行报错。
以上SQL语句在Mysql数据库中可以执行,但是执行结果矛盾。
在SQL语句中若有group by 语句,那么在select语句后面只能跟分组函数+参与分组的字段。
如果想对分组数据再进行过滤需要使用having子句;
取得每个岗位的平均工资大于2000;
select job, avg(sal) from emp group by job having avg(sal) >2000;

分组函数的执行顺序:
● 根据条件查询数据
● 分组
● 采用having过滤,取得正确的数据
一个完整的select语句格式如下:
select 字段
from 表名
where …….
group by ……..
having …….(就是为了过滤分组后的数据而存在的—不可以单独的出现)
order by ……..
以上语句的执行顺序
● 首先执行where语句过滤原始数据
● 执行group by进行分组
● 执行having对分组数据进行操作
● 执行select选出数据
● 执行order by排序
原则:能在where中过滤的数据,尽量在where中过滤,效率较高。having的过滤是专门对分组之后的数据进行过滤的。


