Java多线程编程
“分而治之”是一个有效的处理大数据的方法,著名的MapReduce就是采用这种分而治之的思路. 简单点说,如果要处理的1000个数据,但是我们不具备处理1000个数据的能力,可以只处理10个数据, 可以把这1000个数据分阶段处理100次,每次处理10个,把100次的处理结果进行合成,形成最后这1000个数据的处理结果。
把一个大任务调用fork()方法分解为若干小的任务,把小任务的处理结果进行join()合并为大任务的结果。
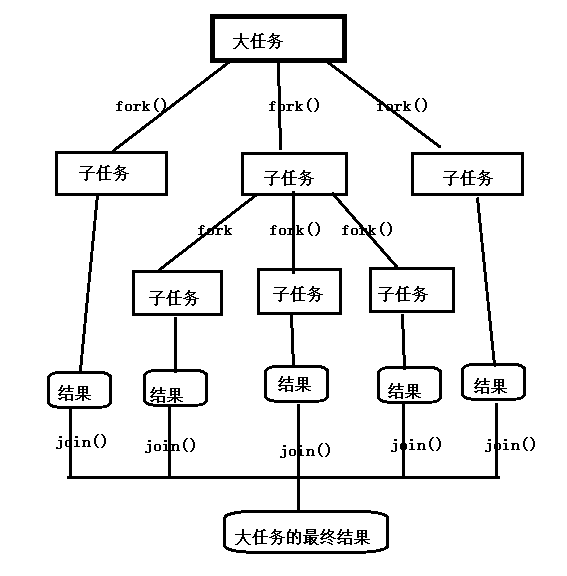
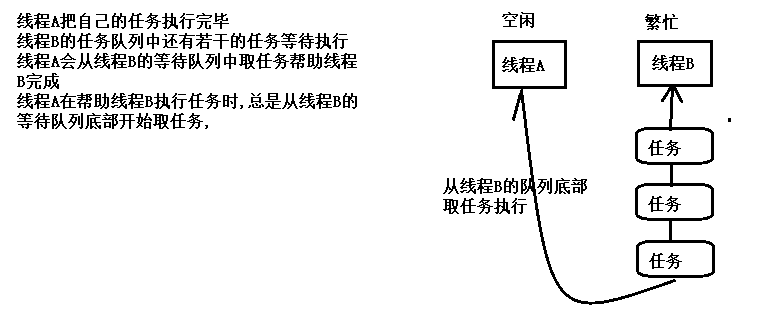
系统对ForkJoinPool线程池进行了优化,提交的任务数量与线程的数量不一定是一对一关系.在多数情况下,一个物理线程实际上需要处理多个逻辑任务。
ForkJoinPool线程池中最常用的方法是:
ForkJoinTask submit(ForkJoinTask task) 向线程池提交一个ForkJoinTask任务. ForkJoinTask任务支持fork()分解与join()等待的任务. ForkJoinTask有两个重要的子类:RecursiveAction和 RecursiveTask ,它们的区别在于RecursiveAction任务没有返回值, RecursiveTask 任务可以带有返回值。
package com.wkcto.threadpool;
import java.util.ArrayList;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* 演示ForkJoinPool线程池的使用
* 使用该线程池模拟数列求和
*/
public class Test09 {
//计算数列的和, 需要返回结果,可以定义任务继承RecursiveTask
private static class CountTask extends RecursiveTask<Long>{
private static final int THRESHOLD = 10000; //定义数据规模的阈值,允许计算10000个数内的和,超过该阈值的数列就需要分解
private static final int TASKNUM = 100; //定义每次把大任务分解为100个小任务
private long start; //计算数列的起始值
private long end; //计算数列的结束值
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
//重写RecursiveTask类的compute()方法,计算数列的结果
@Override
protected Long compute() {
long sum = 0 ; //保存计算的结果
//判断任务是否需要继续分解,如果当前数列end与start范围的数超过阈值THRESHOLD,就需要继续分解
if ( end - start < THRESHOLD){
//小于阈值可以直接计算
for (long i = start ; i <= end; i++){
sum += i;
}
}else { //数列范围超过阈值,需要继续分解
//约定每次分解成100个小任务,计算每个任务的计算量
long step = (start + end ) / TASKNUM;
//start = 0 , end = 200000, step = 2000, 如果计算[0,200000]范围内数列的和, 把该范围的数列分解为100个小任务,每个任务计算2000个数即可
//注意,如果任务划分的层次很深,即THRESHOLD阈值太小,每个任务的计算量很小,层次划分就会很深,可能出现两种情况:一是系统内的线程数量会越积越多,导致性能下降严重; 二是分解次数过多,方法调用过多可能会导致栈溢出
//创建一个存储任务的集合
ArrayList<CountTask> subTaskList = new ArrayList<>();
long pos = start; //每个任务的起始位置
for (int i = 0; i < TASKNUM; i++) {
long lastOne = pos + step; //每个任务的结束位置
//调整最后一个任务的结束位置
if ( lastOne > end ){
lastOne = end;
}
//创建子任务
CountTask task = new CountTask(pos, lastOne);
//把任务添加到集合中
subTaskList.add(task);
//调用for()提交子任务
task.fork();
//调整下个任务的起始位置
pos += step + 1;
}
//等待所有的子任务结束后,合并计算结果
for (CountTask task : subTaskList) {
sum += task.join(); //join()会一直等待子任务执行完毕返回执行结果
}
}
return sum;
}
}
public static void main(String[] args) {
//创建ForkJoinPool线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//创建一个大的任务
CountTask task = new CountTask(0L, 200000L);
//把大任务提交给线程池
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
Long res = result.get(); //调用任务的get()方法返回结果
System.out.println("计算数列结果为:" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//验证
long s = 0L;
for (long i = 0; i <= 200000 ; i++) {
s += i;
}
System.out.println(s);
}
}


